Visit
0 upvotes
Generate Realistic Speech with Advanced AI
Voxtral TTS is an advanced AI text-to-speech platform designed to turn written content into natural, expressive, and human-like voice. It focuses not just on accurate pronunciation, but on delivering speech with realistic tone, rhythm, and emotional nuance, making the output feel closer to real human communication.
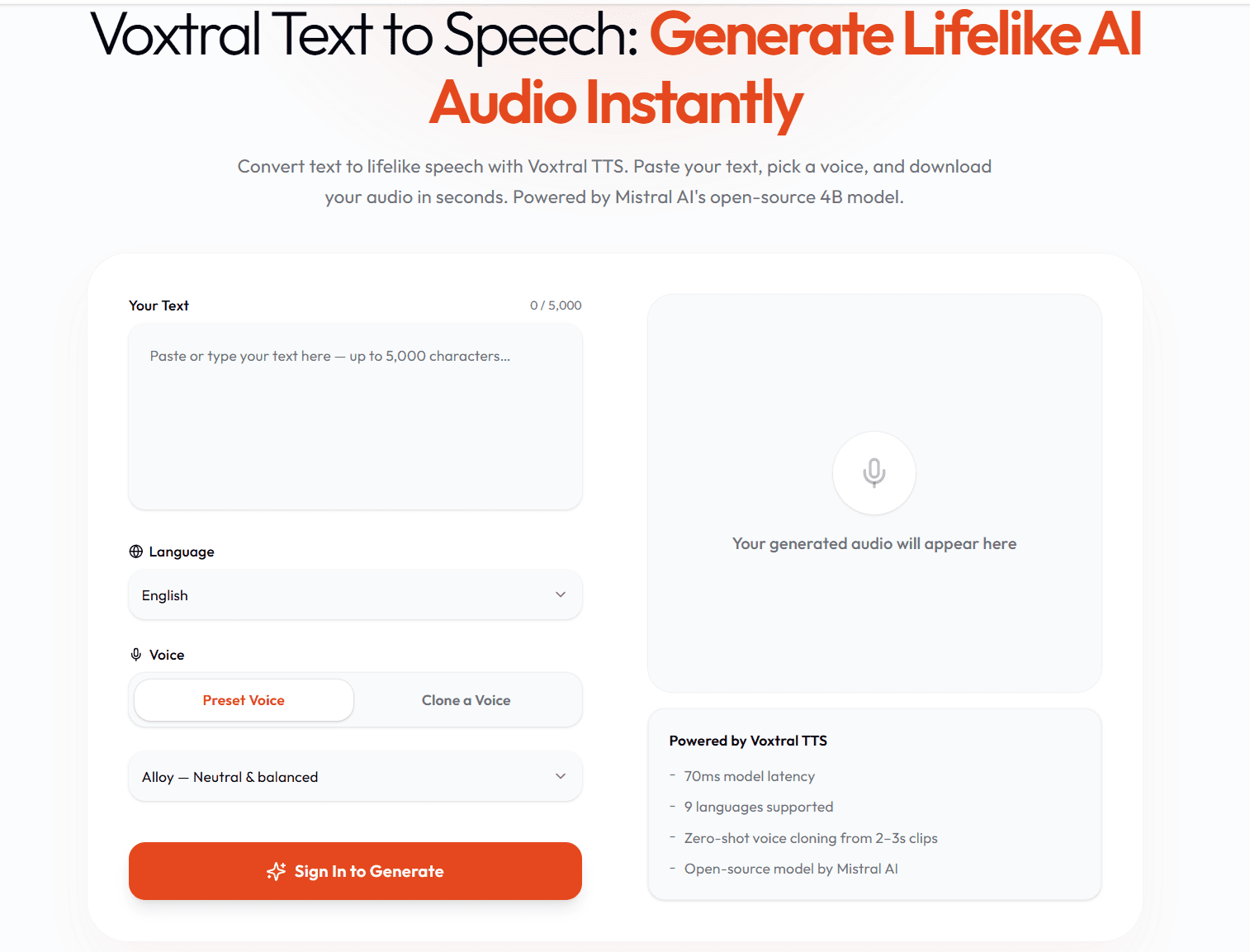
Text-to-Speech Studio
Input Your Text
Simply enter or paste your text, whether it’s a short sentence or a long script.
Select Voice
Choose from high-quality voice models or create a custom voice using voice cloning.
Customize Settings
Adjust parameters like speed, pitch, tone, and language to match different scenarios.
Generate Audio
Produce smooth, lifelike speech instantly with minimal delay.
What is Voxtral TTS?
Voxtral TTS is a next-generation speech synthesis system that goes beyond traditional TTS by focusing on how speech is delivered. It captures subtle elements such as pauses, emphasis, and flow, allowing generated audio to sound more natural and engaging rather than robotic or flat.
Key Features
Natural & Expressive Speech
Generates voice with realistic pacing, tone variation, and emotional depth.
Zero-Shot Voice Cloning
Enables instant voice replication from a short audio sample without training, making personalization fast and accessible.
Multilingual Consistency
Supports multiple languages while maintaining the same voice identity across different outputs.
Real-Time Performance
Low-latency generation makes it suitable for interactive and live applications.
Scalable & Flexible Integration
Provides API access for seamless integration into apps, platforms, and enterprise workflows.
Why Choose Voxtral TTS
More Human-Like Output
Focuses on expression and delivery, not just pronunciation, resulting in more believable speech.
Efficient Content Creation
Reduces the need for manual recording, editing, and voice production.
Easy to Use, Powerful Results
Offers a simple workflow while delivering professional-level audio quality.
Adaptable Across Scenarios
Works well for both creative projects and technical implementations.
Use Cases
Video narration and media production
AI voice assistants and conversational systems
Customer service automation
E-learning and accessibility tools
Comments
Publisher

sarah wilson
Launch Date2026-04-22
Platformweb
Pricingfree
Tags
#voice cloning#text to speech#voxtral tts free#ai voice generator